Extracting Domain Models from Natural-Language Requirements: Approach and Industrial Evaluation
Chetan Arora, Mehrdad Sabetzadeh, Lionel Briand, and Frank Zimmer. 2016. Extracting domain models from natural-language requirements: approach and industrial evaluation. In Proceedings of the ACM/IEEE 19th International Conference on Model Driven Engineering Languages and Systems (MODELS '16). ACM, New York, NY, USA, 250-260. DOI: https://doi.org/10.1145/2976767.2976769
Аннотация
Создан современный парсер для разбора технического задания для того, чтобы автоматически построить UML-диаграмму будущей системы, которую нужно запрограммировать. С помощью парсера создается разметка частей речи и синтаксических конструкций (глагольными и существительными). Таким образом создан код, который генерирует по техническому заданию на естественном языке UML-диаграмму классов. Из всех отношений система выделила 90%, формально верных. Однако, степень релевантности равна 36%. Т.е. 2/3 диаграммы должно быть исключено, так как либо эта часть слишком детализирована, либо наложенные ограничения слишком слабые. Было взято четыре технических заданий, которые были показаны одному эксперту. И этого технического задания была выделена треть требований, которые потом валидировались специалистом. Таким образом, в статье обосновывается, что NLP к подобным задачам применим и показывает неплохую полноту. Но полученный алгоритм очень субъективен и не может быть улучшен с помощью формальных правил. Требуется ML с учителем.
Введение
Предметом данной статьи является разработка автоматического решения для извлечения доменных моделей из «неограниченных» требований к естественному языку. Данная статья сосредотачивается на ситуации, когда невозможно сделать сильных предположений о синтаксе требований, структуре или процессе, в результате которого требования будут выявлены. Рассмотрено использование UML диаграмм классов для представления извлеченных моделей. Существующие решения опираются на некоторые ограничения в синтаксе и структуре естественного языка, которые не всегда можно соблюсти. Современные NLP парсеры предоставляют подробную информацию о связях между различными частями предложения. Проведя исследование существующих экстракторов, авторами было обнаружено, что некоторые крайне полезные возможности не используются: класс правил, называемый ссылочными путями (или синтаксическими ограничениями) позволяет извлекать связи между связанными косвенным образом концепциями. Отношения ссылочных путей могут иметь разную глубину. Каждый уровень глубины представляет собой число дополнительных отношений, связанных с прямым отношением.
Этапы алгоритма
Подход авторов статьи – это пайплайн из трех этапов. На вход подается документ с требованиями на естественном языке, на выходе - диаграмма UML. В пайплайне три этапа: обработка требований, «подъем» зависимостей до семантических единиц, конструирование модели.
- Обработка требований
Данный этап включает в себя: определение фразовой структуры требований, определение зависимостей между словами, разрешение местоименной когерентности, удаление стоп-слов и лемматизация. Это типичные NLP задачи Первые три задачи решаются с помощью стендфордского парсера. Он же предоставляет разметку NP и VB. Важно, что полученные NP атомарны, т.е. не могут быть дальше разделены. Полученные NP и VB являются основой для шага 3 – разметки концептов, атрибутов и связей в доменной моделе.
- «Подъем» зависимостей до семантических единиц
Стенфордский парсер выдает связи на уровне слов. Однако, многие зависимости имеют смысл для извлечения модели только на уровне NP, которые вместе с глаголами являются главным семантической единицей предложения. Чтобы получить из зависимости это значимое отношение для доменной модели, необходимо поднять зависимость на уровень, включающий NP.
- Конструирование модели
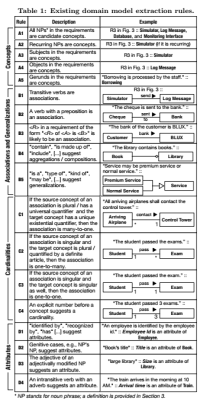
По результатам шагов 1 и 2 строим модель, применяя правила из таблицы 1, из таблицы 2 и ссылочные пути. Всё описание поделено на несколько частей: доменные концепты, связи (ассоциации), обобщения, кардинальности (мощности множеств, числа и тд) и атрибуты.
Доменные концепты: Все извлеченные NP (с шага 1) рассматриваются, как кандидаты в концепты. Если некий NP отмечен, как источник или выход некоторой зависимости, то он помечается, как доменный концепт. Если источник зависимости или ее выход является местоимением, то тот концепт, к которому относится местоимение помечается, как доменный концепт. В таблице 1 первые пять правил (A1-A5), которые отвечают за идентификацию доменных концептов. После удаления стоп-слова, также удаляется прилагательное, если оно стоит в начале, а оставшуюся часть помечается, как доменный концепт. Связь между доменным концептом и доменным концептом с прилагательным устанавливается по правилу D3, использование которого описано в секции Обобщение.
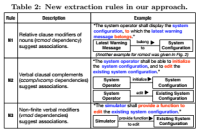
Ассоциации: Глагол, который имеет или субъект, или объект, или и то и другое становится ассоциацией. Как часть с субъектом будет обозначена, зависит от предложения. Таблица 4 содержит типы субъектов. Разработка авторов унифицирует и обобщает правила B1 и B2 из таблицы 1. Для извлечения ассоциаций в дальнейшем предлагается три новых правила N1-N3, отображенные в таблице 2.
- Правило N1 использует зависимости с типом «относительный модификатор предложения»
- Правило N2 использует зависимости с типом «словесное придаточное дополнение»
- Правило N3 использует неконечный вербальный модификатор
Ассоциации, полученные из обобщения правил B1, B2 и от новых правил N1-N3, подвергаются вторичному процессу, целью которого является вычисление ссылочных путей.
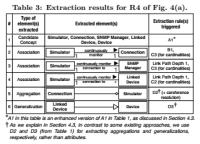
Для извлечения агрегаций, которые являются специальными ассоциациями, означающими отношение вложенности, использовалиcь правила B4 и B2 из таблицы 1. Что касается D2, отмечено, что оно использовалось в нескольких предыдущих работах для идентификации атрибутов. Ларман указывает на сложность в выборе между агрегацией и атрибутом. Он рекомендует любые сущности, которые в реальном мире представляют что-то другое (не строку или число) представлять, как доменный концепт, а не атрибут. Следуя этой рекомендации, d2 использовалось для извлечения агрегаций. Важным замечанием касательно D2 является то, что оно может быть скомбинировано вместе с когерентным разрешением. По мнению авторов, раньше подобный метод не использовался для извлечения моделей. Пример такой комбинации можно найти в строке 5 таблицы 3. Авторы предполагают, что обобщения в требованиях на естественном языке обычно выражены неявно. Таким образом их трудно идентифицировать с помощью автоматических методов. Главным правилом для извлечения обобщений является правило B5 из таблицы 1.
Кратность: Используются правила C1-C4 из таблицы 1 для определения отношения кратности. Эти правила основаны на числительных, появляющихся рядом с термами, которые представляют доменный концепт.
Атрибуты: Использовались правила D1-D4 из таблицы 1, для извлечения атрибутов. Как обсуждалось ранее, D2 и D3 были использованы для извлечения агрегаций и обобщений. В отношении D4 отмечено, что трудно однозначно назвать имя атрибута, тем не менее, по сравнению с правилом D3, которое неприменимо без пользовательского вмешательства, D4 может обоснованно угадывать имя атрибута.
Оценка подхода с точки зрения трех исследовательских вопросов
- Как часто различные правила использовались? Нельзя ожидать большой пользы от правила, которое используется редко. Частая используемость правила, таким образом, становится показателем его полезности. Первый исследовательский вопрос ставит своей целью померить число раз, когда различные правила были использованы в промышленных требованиях.
- Насколько полезен наш подход? Полезность нашего подхода, в конечном счете, зависит от того, найдут ли практики наш подход полезным в реальной ситуации. ИВ2 ставит своей целью сделать подобную оценку через пользовательское исследование корректности и релевантности результатов, полученных с помощью нашего метода
- Является ли время работы нашего подхода практичным? Документы с требованиями могут быть очень большими. Необходимые вычисления модели должны происходить быстро.
Реализация
Для синтаксического разбора и когерентного разрешения использовался стэндфордский парсер. Для лемматизации и удаления стоп-слов - существующие модули из GATE NLP Workbench. Реализация извлечения модели проведена с использованием скриптового языка GATE, JAPE, Java и окружения для GATE. Извлеченные диаграммы классов представлены в виде логических предикатов. Итоговая реализация занимает примерно 3500 строк кода, исключая комментарии и сторонние участки кода.
Результаты и оценка экспертом
Метод применен на 4 документах, 2 из которых создатели пытались делать по некоторым шаблонам (64% и 89% соответствия шаблонам)
- ИВ1: Авторы обнаружили, что новые правила, которые они ввели, были часто использованы, акцентируя на то, что link path был задействован ощутимое количество раз. Заключают, что особой пользы или вреда от задействования шаблонов в документах ими не было. Впрочем, замечают они, у них не было специальных правил под эти шаблоны, а значит можно добиться лучшего результата, если их придумать.
- ИВ2 (постановка задачи): Проведен опрос эксперта. Из одного документа было выделено 50 требований системы. И на этих требованиях запущен алгоритм.. По каждому найденному отношению эксперт должен был ответить на два вопроса: корректно ли отношение (да, нет, не совсем), должно ли отношение быть в доменной модели (да, нет, возможно). Также эксперта просили указать на ненайденные связи.
- ИВ2 (результат): Эксперт ответил, что 90% найденных отношений корректны. Также по результатам экспертной оценки вышло, что только 36% найденных отношений стоит (или возможно стоит) включить в доменную модель. То есть 2/3 результата автоматики нужно исключить. Так как выборка крайне мала, авторы использовали бутсреппинг, чтобы получить доверительные интервалы. Авторы признаются, что в виду такой корректности их метод дешевле не использовать, чем использовать. Отмечаются, что повышение корректности - это отличное направление для дальнейших работ. В таблице 8 приведены причины, по которым эксперт отмечал найденные отношения, как неверные.
- ИВ3: На ноутбуке 2.3 GHz CPU и 8 гигабайтах оперативной памяти обработка самого тяжелого документа (380 требований) заняла 4 минуты. Из чего заключают, что результат неплохо масштабирован.
- Своей целью авторы поставили показать эффективность использования методов NLP в задаче извлечения модели.
Заключение
Представлен автоматический подход, основанный на методах NLP для извлечения доменных моделей при неограниченных требованиях. Главным техническим вкладом подхода является расширение существующего множества правил извлечения. В статье представлена оценка подхода, с указанием на понимание в пока еще ограниченное знание об эффективности извлечения модели в промышленных условиях. Ключевой особенностью нахождения оценки является то, что заметная часть автоматически извлеченных отношений не является релевантной по отношению к доменной модели. Хотя могие из этих отношений имеют смысл. Улучшение корректности – это сложная задача, которую авторы предполагают рассмотреть в будущих работах. В частности, требуется дополнительное исследование для проверки того, что наблюдения относительно корректности воспроизводимы. Если воспроизводимость подтвердится, то потребуются технические улучшения для увеличения корректности. В конце концов ключевым фактором для рассмотрения некого отношения, как корректное или некорректное, является контекст. Подобного рода инормация, как правило, скрыта и не может быть автоматически извлечена. Увеличение корректности, таким образом, потребует вовлеченности человека в процесс извлечения модели, позволяя эксперту объяснять их скрытое знание. Авторы уверены, что подобного рода стратегия будет работать наилучшим образом в том случае, если она будет инкрементальной. Под этим подразумевается, что эксперт может предлагать свое видение в рамках серии шагов, параллельно оценивая результаты автоматики. Такое скрытое знание может быть использовано не только для восполнения пробелов в доменной модели, но также и для обучения, например, методов машинного обучения.
Ссылки
ACL Digital Library https://dl.acm.org/citation.cfm?id=2976769&CFID=844850077&CFTOKEN=52790660
Приложения